
3 Levers for Vertical AI (or Departmental AI)

Share to
The model is the commodity. The moat is the last mile.
In a world where OpenAI, Anthropic, and Google are spending hundreds of billions to build the most capable general-purpose models on earth, the obvious question is why vertical AI needs to exist at all. Why don't the foundation models just eat everything?
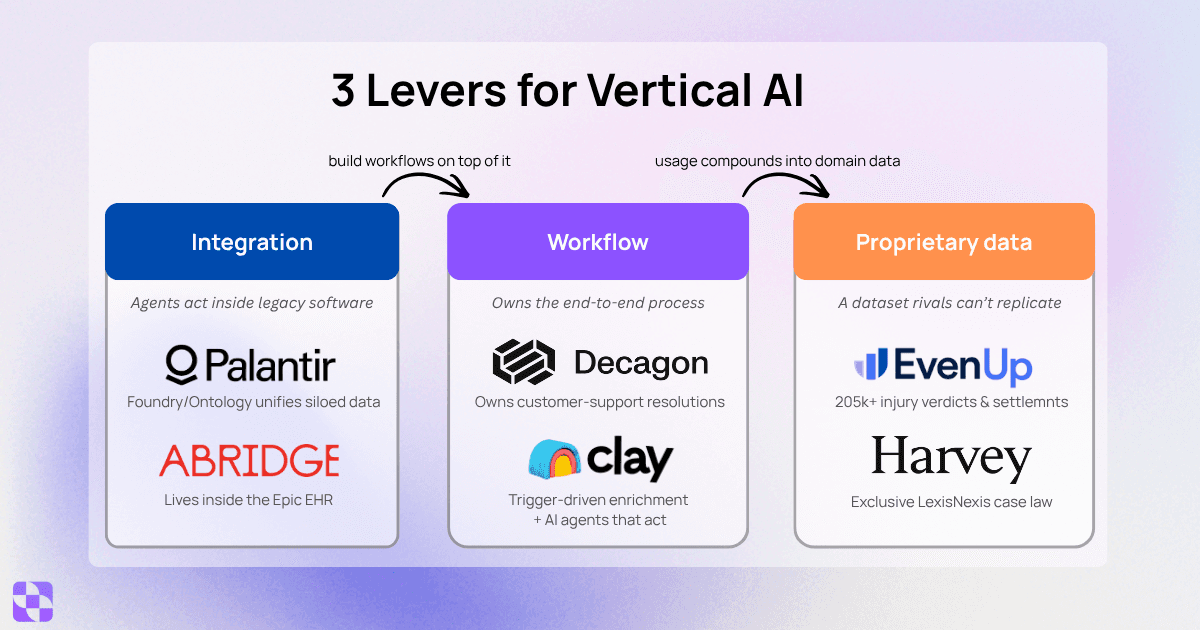
I went deep on this, and the answer is cleaner than the noise around it suggests. The model is the commodity. You can swap Claude for GPT for Gemini in an afternoon. The moat is everything wrapped around it, which is what a16z calls "the last mile" and what Bessemer's vertical-AI playbook circles from a different angle. Pull it all together and it comes down to three levers a horizontal provider structurally can't pull for you.
Lever 1: Integration (operate the software you already run)
The first lever is getting the AI to reach into and operate the systems a business already lives in: the EHR, the CRM, the 20-year-old database nobody wants to touch. A general chatbot can't do this. It has no hands inside your stack.
Abridge is the cleanest example. It lives inside Epic, so a doctor's note flows straight into the patient chart without ever leaving the system. Palantir built an entire company on this: Foundry exists to unify messy, siloed enterprise and government data. Mastering software like Epic, Guidewire, or a bank's core takes years of grinding work. The labs won't do that for each customer. You can.
Lever 2: Workflow (run the whole process end to end)
The second lever is owning the multi-step process, not just answering a question. A chatbot responds. A workflow product takes the whole job (intake, draft, review, approval) and runs it, with the AI as one orchestrated step among human checkpoints.
This is where automation, not just assistance, actually shows up, and it's where you become load-bearing. There's hard data behind that distinction. Anthropic's Economic Index, which maps millions of real Claude conversations to actual job tasks, found that usage of its consumer chat assistant leans toward augmentation (roughly 57% augmentation vs 43% automation), while its embedded, programmatic API traffic skews the other way, toward automation. The tell: real automation doesn't happen in a chat box. It happens when the model is wired into a workflow and handed something to run.
Decagon doesn't "help with support tickets." It owns the resolution process end to end. Once a team's daily operations run through you, ripping you out means rebuilding how they work. That switching cost is the moat.
Lever 3: Proprietary data (build data rivals can't copy)
The third lever is a dataset no one else has, that gets sharper the more you're used. General models are trained on the public internet; the value in a vertical comes from private, authoritative, compounding data.
EvenUp built a 250K+ corpus of injury verdicts and settlements no competitor can match, and every case it processes makes the next one better. Harvey didn't even have to build its own: the LexisNexis alliance handed it exclusive access to authoritative case law that a foundation model legally can't train on. Data is the moat that compounds.
The real insight: win one, then build the other two
Here's the part most people miss. You don't need all three to get started. You win product-market fit on one sharp wedge.
But PMF is not a moat. The durable companies treat their first lever as a foothold and then climb. The classic path: you start by letting users operate their legacy software through an agent (integration). That earns the right to automate the steps around it (workflow). And running those workflows generates domain data that makes the product more and more specific to the vertical (proprietary data).
Each layer deepens the next. It compounds into a flywheel, and that is what a foundation model can't replicate, because it requires the grinding, unglamorous work of going firm-by-firm, team-by-team.
One honest caveat: the three aren't equally defensible. Integration tends to be a wedge. It gets you in the door, but it's the easiest to copy, and emerging standards like MCP are commoditizing it fast. Workflow lock-in and proprietary data are what actually protect you over time. There are also levers I'm leaving out to keep this focused, such as governance, multimodality, and network effects. Network effects may be the deepest of all.
Why this matters right now
The bottleneck in enterprise AI has moved from the model to deployment. Something like 95% of generative AI pilots never reach production, and almost never because the model wasn't smart enough. They die on integration, workflow redesign, and governance.
That's the whole story behind the explosion of the "forward-deployed engineer" role, and why even OpenAI and Anthropic are now copying Palantir's deployment playbook. When the model is commodity, the last mile is the moat.
So if you're building vertical or departmental AI: pick your wedge, win it, then climb. Own one lever, build the other two, and you become the thing a general model can't rip out.
Sources: Anthropic Economic Index (augmentation vs automation); Bessemer's Building Vertical AI playbook; a16z's In Defense of Vertical Software.