Feb 17, 2026
Context Bus
Memory

Every time you switch from ChatGPT to Claude, you start over. Every time your AI agent hands off work to another agent, context evaporates. Every time a new teammate asks "why did we build it this way?", their AI assistant draws a blank.
We've solved storage. We've solved retrieval. But we haven't solved the thing that actually matters: making context flow between the people and AI systems that need it.
This is the problem the Context Bus solves.
The real problem isn't memory, it's the plumbing
People use multiple AI tools. ChatGPT for drafting. Claude for code. Gemini for brainstorming. Every switch means lost context, re-explained preferences, and manual copy-pasting.
But that's just the surface. The deeper issue is that we're entering an era of AI agents. Systems that research, write, plan, and review on your behalf. And none of them can link to what the others know.
A research agent can't hand its findings to a writing agent. A writing agent can't inherit your style preferences from last week. A new hire's AI assistant can't access the decisions that shaped the codebase. Every workflow is a series of cold starts.
The existing solutions don't fix this:
RAG and vector search: find similar documents, but don't remember your preferences or track how your work evolved.
Conversation Agent Memory: extracts facts and episodes from chat history, but loses the actual outputs — the blog post, the strategy doc, the checklist.
Agent frameworks: pass state between agents, but nothing persists across workflows. Every pipeline is bespoke plumbing.
Manual context files: (like system prompts or Claude.md) work early on, but go stale as your work evolves.
What's missing is a system that understands three things: what was produced, what was learned along the way, and who needs that context next.
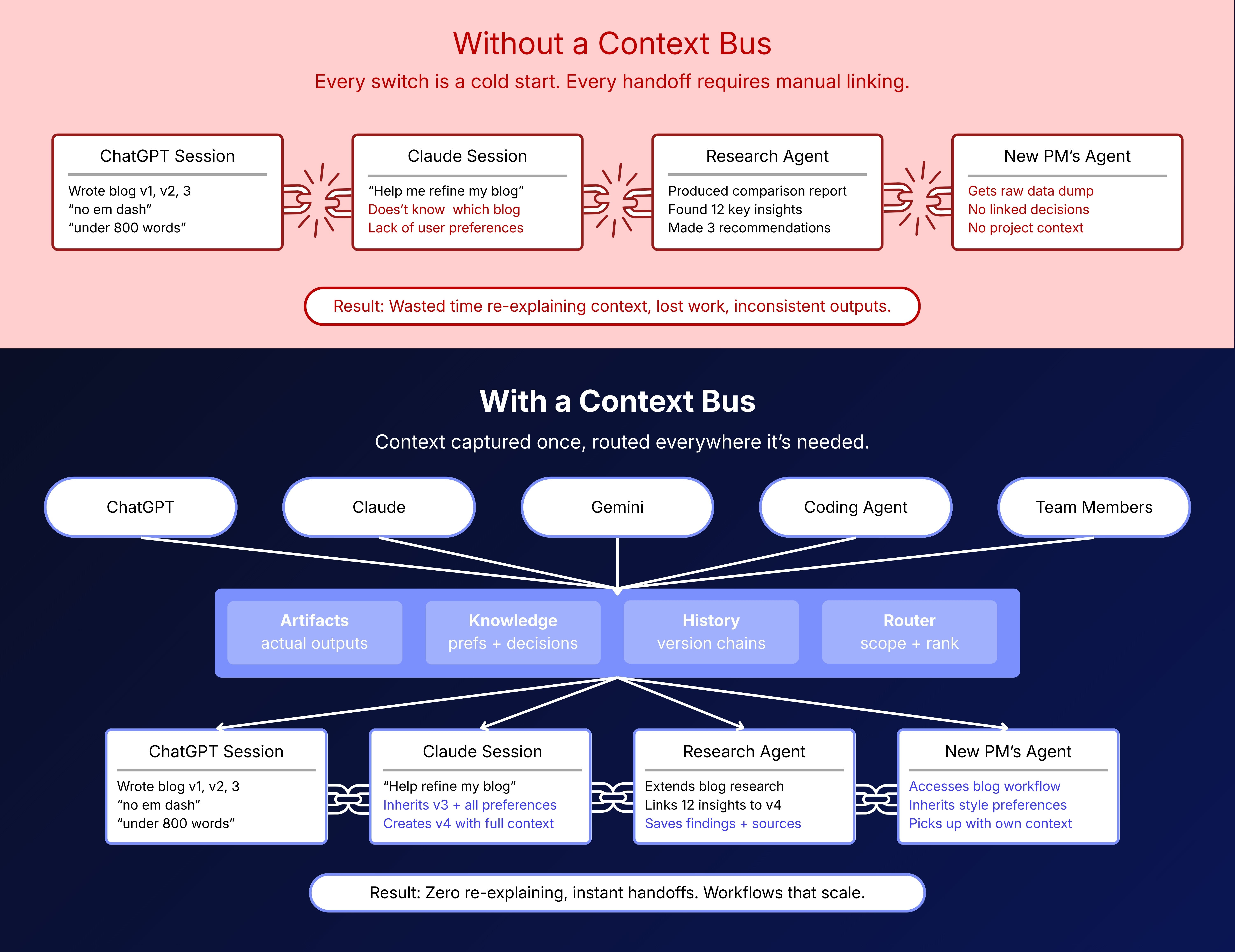
What we are building
The Context Bus sits between anything that produces context (you, your AI tools, your agents) and anything that consumes it (a different AI tool, a different agent, a teammate).
It captures three things every time work happens:
Artifacts: the actual outputs. The blog post. The competitive analysis. The architecture doc. Not a summary, not metadata. The real thing.
Knowledge: the preferences, decisions, and context accumulated while creating those artifacts. "No em dashes." "We chose Postgres for ACID compliance." "This is for the Q1 launch."
History: how artifacts evolved. Version 1 in ChatGPT. Version 2 after your feedback. Version 3 refined in Claude. The full chain.
These three are deeply linked. A preference only matters in the context of an artifact. An artifact only makes sense with its history. The Context Bus captures all three, links them together, and routes the right combination to whoever needs it.

What this looks like in practice
Switching between AI tools without starting over
Alex is writing a launch announcement in ChatGPT. After three rounds of edits, they've dialed in the formatting: no em dashes, tight paragraphs, under 800 words. The post is at version 3.
Later, Alex switches to Claude: "Help me tighten the intro of my blog post."
Today, Claude has no idea what blog post Alex means. Alex pastes the whole thing in, re-explains the rules, and loses the version history.
With the Context Bus, the system matches "my blog post" to the right artifact, injects the latest version along with Alex's preferences, and Claude picks up mid-stride. No re-explaining. No copy-pasting.
Agents that actually share what they know
A product team tasks a research agent with comparing payment processors. Stripe vs. Braintree vs. Paddle. The agent produces a detailed comparison.
Next, a strategy agent needs those findings to draft a pricing plan. Later, a review agent needs to check whether the pricing plan aligns with the research.
Today, a developer manually wires state between these agents. The strategy agent gets a raw dump of everything. The review agent gets nothing.
With the Context Bus, the research report is stored with linked facts: "Stripe has the best API docs," "Paddle handles EU VAT," "team prioritizes simplicity over cost." When the strategy agent asks for context, it gets the relevant research and decisions. When the review agent checks the plan, it gets the plan and the original research side by side. No manual wiring. No lost context between steps.
Teams that remember why decisions were made
Priya joins a fintech startup as a backend engineer. On day two, she asks her AI assistant: "Why did we choose event-sourcing for billing?"
Today, the assistant has no context. Priya spends three days reading architecture docs, Slack threads, and pull requests.
With the Context Bus, the system retrieves the architecture design doc (version 3, evolved across three sessions), the key decisions ("chose event-sourcing after a failed audit revealed we couldn't reconstruct transaction history"), and the regulatory context that drove the decision. Priya understands not just what was decided, but why. In minutes, not days.
Work that spans months without losing the thread
Sam has been writing a technical book, one chapter at a time. Chapter 1 was drafted in ChatGPT in January. Chapters 2 through 4 were written in Claude over February and March, with accumulated feedback along the way: "more concrete examples," "shorter paragraphs," "avoid undefined jargon.”
In June, Sam returns: "Help me write chapter 5."
Today, no AI tool remembers any of it. Sam pastes the last chapter, re-explains the style rules, and hopes for consistency.
With the Context Bus, the system retrieves all four chapters, the full version history, and twelve accumulated writing preferences. Chapter 5 picks up in the same voice, follows the same rules, and references earlier content naturally. Six months of work, zero re-explaining.
Playbooks you can actually reuse
Taylor just finished an eight-week product launch. The GTM strategy was drafted in ChatGPT, customer research happened in Claude, pricing analysis in Gemini, plus blog posts, email templates, and a launch checklist scattered across sessions.
Now a second launch is coming and a new PM is leading it.
Today, the new PM reconstructs the playbook manually, missing key decisions along the way.
With the Context Bus, Taylor creates a "Product Launch" knowledge base from the Q1 work. All artifacts, linked decisions, and version history are grouped together. The new PM's assistant accesses the full playbook, including the reasoning behind every decision. Months of institutional knowledge, transferred in seconds.
Why this is hard
Storage is commodity. Any database can store documents. The hard part is the intelligence layer:
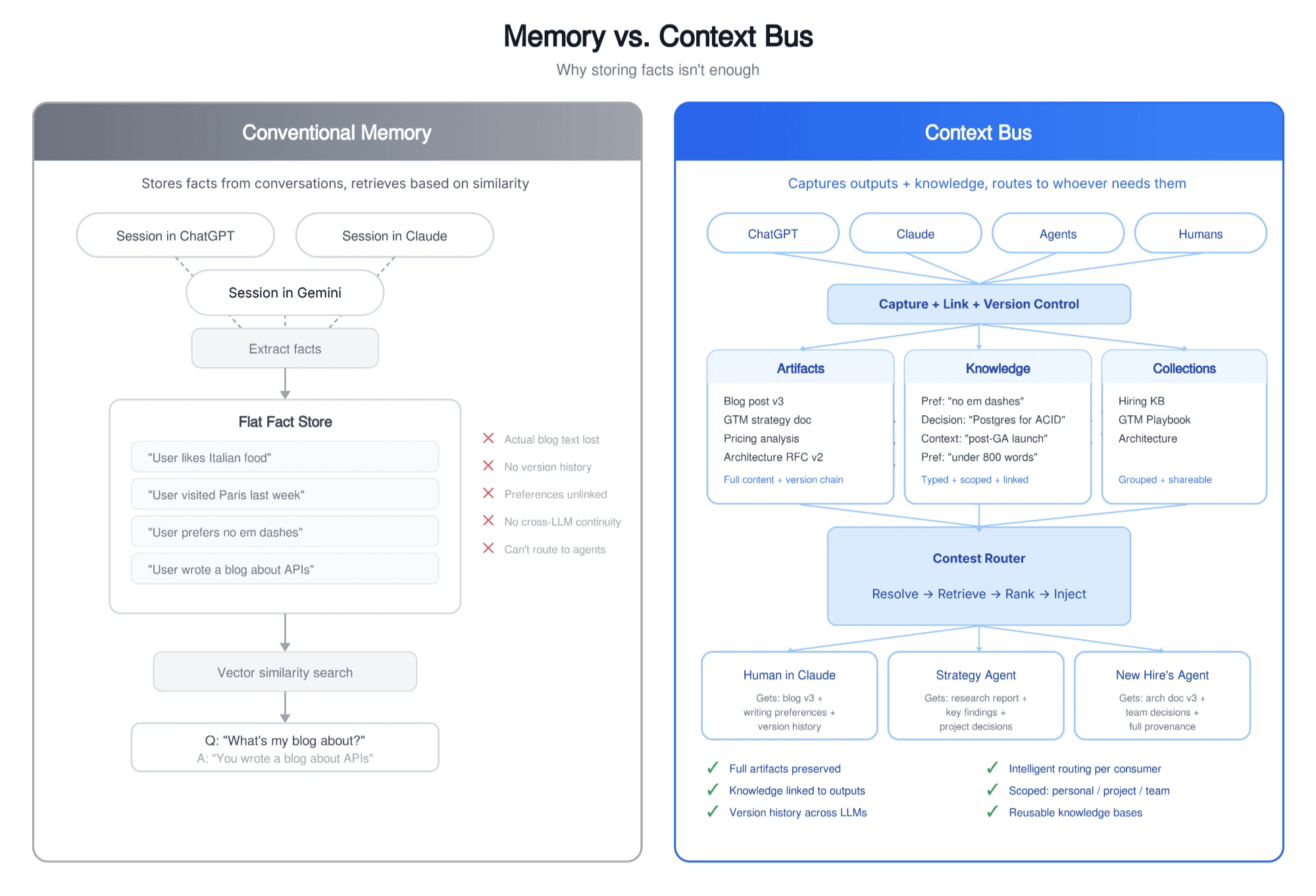
Detection: Knowing that an AI output is something worth keeping versus throwaway conversation. A blog post draft is an artifact. "Sure, here's what I think" is not. This requires understanding intent, structure, and conversation flow, not just content.
Linking: Connecting artifacts to the preferences and decisions that shaped them. The fact that you said "no em dashes" while editing a blog post means that preference is linked to writing artifacts, not to your code reviews. This requires understanding relationships, not just entities.
Routing: Figuring out what context a consumer needs without being told explicitly. When Alex says "my blog post" in Claude, the system needs to resolve that to the right artifact, find the right preferences, and inject both without Alex having to specify an ID or filename.
Scoping: Knowing what's personal versus project versus team. Your writing preferences are yours. An architecture decision belongs to the whole team. A project-specific constraint shouldn't leak into unrelated work.
The more context flows through the system, the better it gets at all four. The intelligence compounds.
The Trust Problem Nobody Talks about
There's a question hiding behind all of this: if the Context Bus stores your most valuable work (strategy docs, architecture decisions, competitive analyses, hiring plans), who else can see it?
With most AI memory and RAG systems, the answer is uncomfortable. Your data gets embedded into vectors, stored in a database, and searched in plaintext. The vendor's infrastructure sees everything. Your documents, your queries, your results. You're trusting application-level access controls to keep your data private. If the vendor is compromised, or just curious, your context is exposed.
The Context Bus is built on XTrace, which takes a fundamentally different approach: your data is never decrypted on the server.
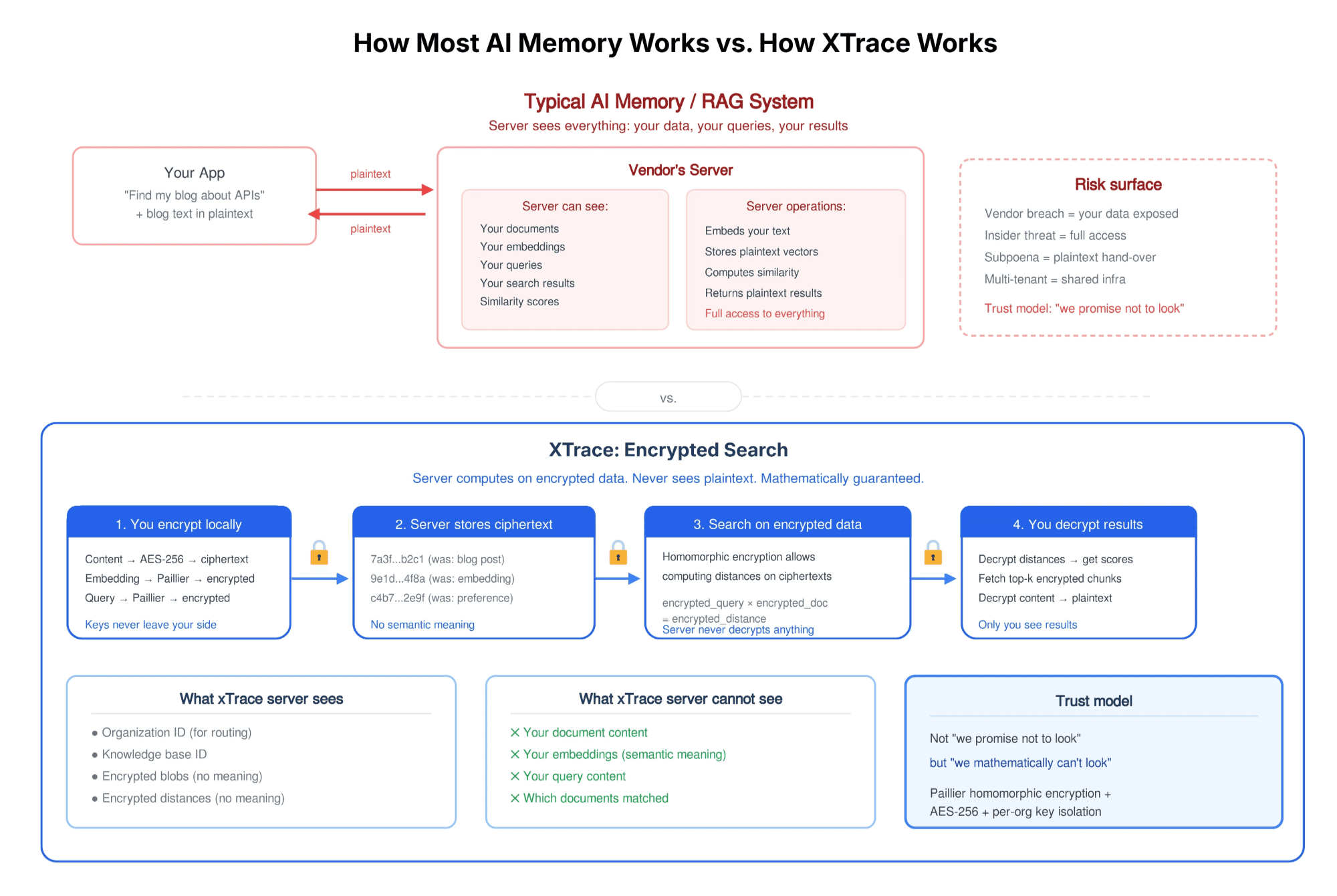
Here's what that means concretely:
Your content is encrypted before it leaves your environment: Every artifact, every fact, every preference is encrypted with AES-256 and Paillier using keys only you hold. The server stores ciphertext (opaque blobs with no semantic meaning).
Search happens on encrypted data: This is the part that sounds almost impossible. xTrace uses homomorphic encryption, a mathematical property that allows the server to compute similarity scores on ciphertexts without ever decrypting them. The server computes encrypted distances, returns encrypted results, and your client decrypts the scores locally. The server never knows which documents matched, how similar they were, or what you were searching for.
Each organization gets cryptographic isolation: Not just access control lists, but separate encryption keys. Your team's execution context has its own key pair. A different organization's context uses entirely different keys. So even if someone accessed the raw database, they'd see nothing but encrypted integers.
For the Context Bus, this matters in a specific way. The scoping problem (personal vs. project vs. team) gets a cryptographic enforcement layer. When we say personal preferences can't leak to team context, that's not a promise enforced by our API layer. It's a mathematical guarantee enforced by separate encryption contexts. There is no key that decrypts both.
This is what makes the "route context to the right consumer" problem solvable for enterprises. A CTO will let architecture decisions and competitive analyses flow through the Context Bus because the infrastructure itself can't read them. Not "won't." Can't.
Where this is going
The scenarios above (switching between LLMs, agents handing off work, teams preserving institutional knowledge) are just the first layer. The bigger picture is what happens when context becomes infrastructure that everything plugs into.
Context as login. Today, "Login with Google" gives an app your identity. Imagine "Connect your Context Bus" giving an app your preferences, your work history, and your decisions, scoped to exactly what that app needs. A new AI writing tool instantly knows your style. A new project management agent inherits your team's architecture decisions. You don't onboard tools anymore. Tools onboard to you.
Agents that share a world model. Right now, every agent in a multi-agent workflow is an island. A research agent finishes its job and its understanding dies with the session. With the Context Bus as shared infrastructure, agents build on each other's work the way teammates do. A code agent knows the research agent found a critical security issue. A QA agent knows the design agent changed the spec yesterday. The bus becomes the shared memory that turns a collection of isolated agents into a team.
Portable context you own. Your preferences, your artifacts, your decisions, stored encrypted, controlled by your keys. Switch from one AI provider to another and your context follows you. Leave a company and your personal context leaves with you. The team context stays behind. This is the data portability promise that cloud storage never delivered, applied to the thing that actually matters: what you know and what you've built.
Organization-wide intelligence. Scale this to a company and something interesting happens. Every decision, every design doc, every competitive analysis ever created by anyone on the team becomes part of a shared, searchable, scopable context layer. A new hire's agent doesn't just get access to docs. It gets access to the reasoning behind every decision. Institutional knowledge stops being tribal and starts being infrastructure.
We're starting with the foundation: reliable artifact capture, linked knowledge extraction, and encrypted storage you can trust. The context router comes next. But the end state isn't a better memory system.
It's the layer that makes every AI tool, every agent, and every team member smarter, because none of them ever start from zero again.

© 2026 XTrace. All rights reserved.