
Belief Revision System


Memory isn’t about storing data. It’s about forming beliefs.
Every AI memory product ships the same pitch: your AI remembers things. Embeddings, vector databases, semantic search. The storage problem is solved. But storage is the easy part. The hard part is what happens after you store something: you change jobs, you drop a hobby, you reverse a decision, a project deadline passes. The facts you stored are now wrong, and the system has no idea.
That’s because memory systems store facts. What they should be maintaining is beliefs: assertions about the world that can be revised, retracted, expired, and protected based on how much they matter.
XTrace is a belief revision system: built on formal epistemology, engineered for portable, multi-agent AI. It doesn’t just remember what you said. It maintains a living trace of what’s true, revises that trace as the world changes, and strengthens or weakens it with every correction.
The endgame is context as login. “Login with Google” gives an app your identity. “Connect your XTrace” gives an app your preferences, your work history, your decisions, scoped to exactly what that app needs. You don’t onboard tools anymore. Tools onboard to you.
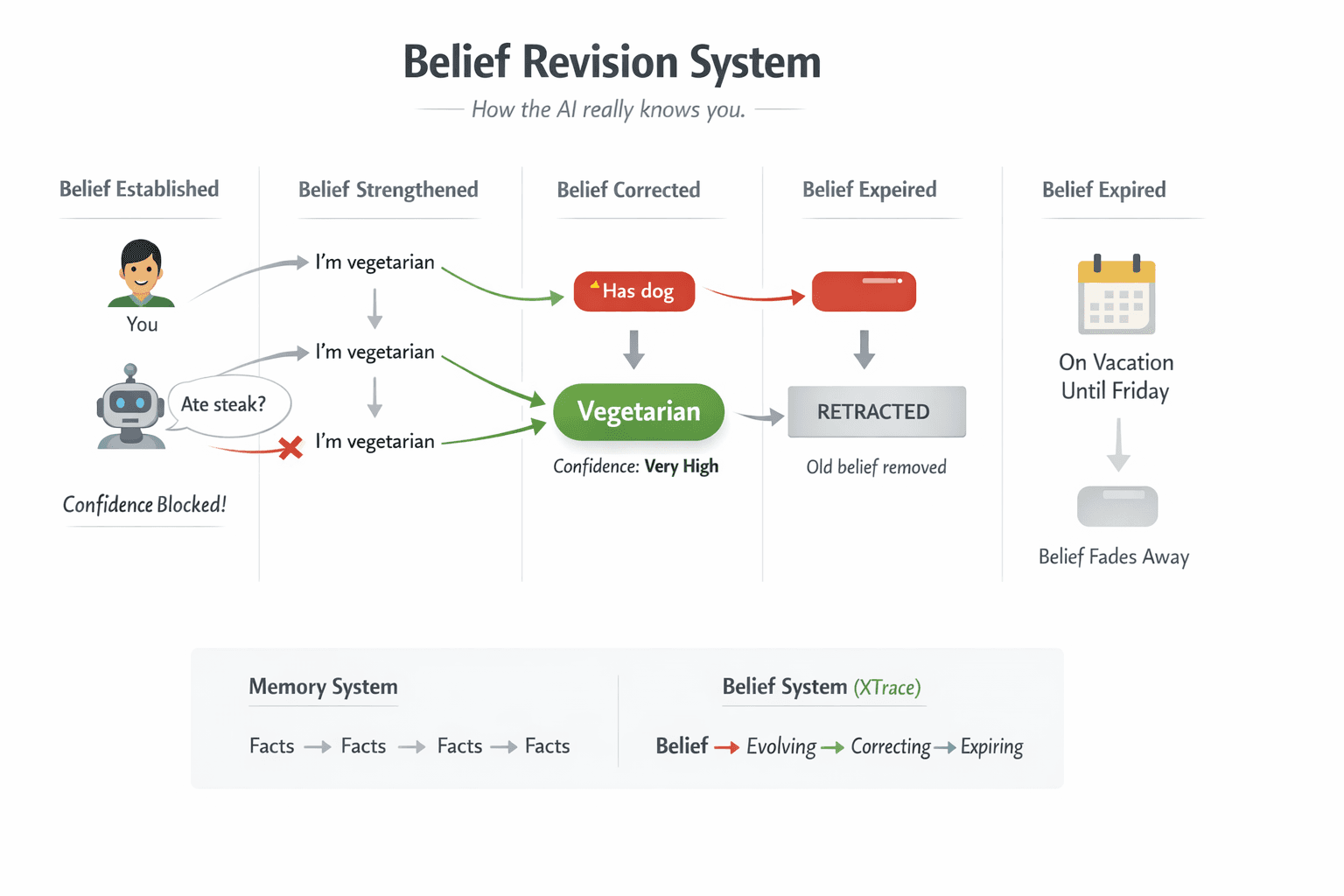
Beliefs and artifacts
The system maintains two kinds of knowledge.
Beliefs are atomic: “user is vegetarian,” “we’re using event-sourcing for billing,” “launch window is 30 days post-GA.” They can be revised when the world changes, retracted when the agent was wrong, or protected when they matter too much to lose. Formal belief revision theory (the AGM model) defines three operations — expansion, revision, contraction — and XTrace implements all three, including contraction: the hard problem of removing a belief with no replacement.
Artifacts are work products: a GTM strategy, a technical design, a blog post. They’re version-chained like git — each revision links to the previous, with the decisions and preferences that drove the change.
Both are connected. Beliefs inform artifacts. When a belief changes, the system knows which artifacts were built on it. This is what makes everything below work.
Session briefings: no more cold starts
Every AI session today is a cold start. You re-explain yourself, re-establish context, re-upload your work. Yesterday’s hour-long strategy discussion? Gone. The decisions you made, the trade-offs you considered, the direction you chose — all trapped in a chat log you’d have to re-read and re-paste.
XTrace eliminates the cold start. At the end of every session, the system extracts what matters: the beliefs established, the decisions made, the artifacts created or revised, the open threads. When you start a new session — same tool, different tool, next day, next month — the agent opens with a briefing:
Here’s where you left off. You’re building a GTM strategy focused on enterprise (not SMB). Key decisions: direct sales motion, not PLG. Open question: pricing tier structure. The positioning document is on v3 — last edit tightened the competitive differentiation section based on your feedback about being too defensive.
No re-explaining. No “let me catch you up.” The agent knows what you’re working on, what you’ve decided, and what’s still open. Session 47 feels like session 1 — but with full context.
The briefing isn’t a transcript summary. It’s a structured model: active beliefs, current artifact versions, unresolved threads. Each piece has provenance — where it came from, when, and why the system believes it. When something is wrong, you correct it once and it’s corrected everywhere.
Artifact handoff: git for cross-intelligence output
You draft a blog post. Three rounds of editing: tighten the intro, add examples, fix the tone. Each round produces a new version, linked to the previous, with the preferences that drove the change. That’s three versions of the artifact, each with context about what changed and why.
Now you switch tools. Different day, different agent. “Help me refine my blog post.” The system resolves the latest version with full history. The new agent doesn’t ask “which blog post?” or “what’s the current draft?” It picks up mid-stride — v3, with your stated preference for concise intros and concrete examples already in context.
This is what makes artifacts different from files in a chat thread. A file is static. An artifact is a living work product with:
Version history. Every revision linked to the previous, with what changed and why.
Linked beliefs. The preferences and decisions that shaped each version. “No em dashes” isn’t a one-time instruction — it’s a belief attached to every writing artifact.
Cross-session identity. The artifact persists across sessions, tools, and agents. It has a stable identity that any consumer can resolve.
When the PM builds a competitive analysis across five sessions, the artifact accumulates everything — not just the latest text, but the research decisions, the discarded alternatives, the reasoning. Hand it off to the engineer and they get the full picture, not a Google Doc with no context.
Sharing context: from “let me catch you up” to instant handoff
The PM spends a week on competitive analysis. Three tools, ten sessions, dozens of decisions. The engineer needs to start the technical design. Today, that handoff is a meeting, a Notion doc, a Slack thread, and a prayer that nothing important was lost in translation.
With XTrace, the PM shares a scoped context: the relevant beliefs, the key artifacts, the decision chain. The engineer’s agent receives a briefing:
The PM’s competitive analysis identified three key differentiators. The strategic decision is enterprise-first, direct sales. This is pinned as a project axiom — it won’t be auto-overridden. The positioning document (v4) and the competitive matrix are attached with full version history. The PM rejected PLG in session 3 because the buyer persona requires high-touch onboarding.
The engineer doesn’t re-read the PM’s chat logs. They don’t schedule a sync. Their agent starts with structured context: what was decided, why, what artifacts exist, and which decisions are load-bearing.
When the PM later changes a decision — “actually, we’re going PLG for the starter tier” — the engineer’s agent flags the impact: “The technical design document was built on the assumption of direct sales only. The pricing model artifact may need revision.” The system doesn’t just update one belief. It traces what depended on it.
Cross-tool continuity: one belief system, every agent
Draft a strategy in Claude. Research competitors in ChatGPT. Build the slide deck in Notion. Each tool connects to the same belief system. Each tool starts with the same context. Each tool’s contributions flow back.
This is “context as login” in practice. The belief system is the shared layer that makes every tool aware of every other tool’s work. The research agent’s findings are already there when the strategy agent starts. The code agent knows the design agent changed the spec yesterday. You stop re-uploading, re-explaining, and re-establishing context across tools.
Corrections propagate too. Tell Claude “we’re NOT doing the Kafka migration” and every connected agent updates. The briefing in ChatGPT reflects the retraction. The project tracker in Notion flags the downstream artifacts. One correction, everywhere, immediately.
Why this works: the belief revision engine
The experiences above are powered by a formal belief revision engine. Without it, context handoff degrades the same way every memory system degrades — stale beliefs, contradictions, hallucinated inferences treated as truth.
Entrenchment. Not all beliefs are equal. Axioms (user-curated core beliefs like “I work at Anthropic”) are never auto-overridden. User-stated beliefs outrank system inferences. The pipeline’s guesses can’t override what you actually said. In a team context, the PM’s project axioms can’t be superseded by a junior engineer’s conversation.
Contraction. “We’re not doing the Kafka migration.” Most systems have no model for removing a belief without a replacement. XTrace handles pure denial — the old belief is retracted, invisible to future retrievals, preserved for lineage. The system distinguishes whether the world changed (the migration was real, now it’s cancelled) or the agent was wrong (there was never a migration plan). Only agent errors feed into learning.
Dependency propagation. When a high-entrenchment belief changes, the system flags what depended on it — downstream beliefs and artifacts. Change jobs and it flags your old email, your old tools, your old workflow preferences. Change a strategic decision and it flags every document built on that assumption.
Learning from corrections. Every correction generates a labeled example of what went wrong. The system searches its revision history for context-similar past mistakes and injects them as guidance before extraction. Month 1: extracts “user prefers Go” from a code review, corrected. Month 3: before a similar extraction, it injects “reviewing code in a language does not imply preference.” No fine-tuning. Just the system’s own history, semantically retrieved and improving with every correction.
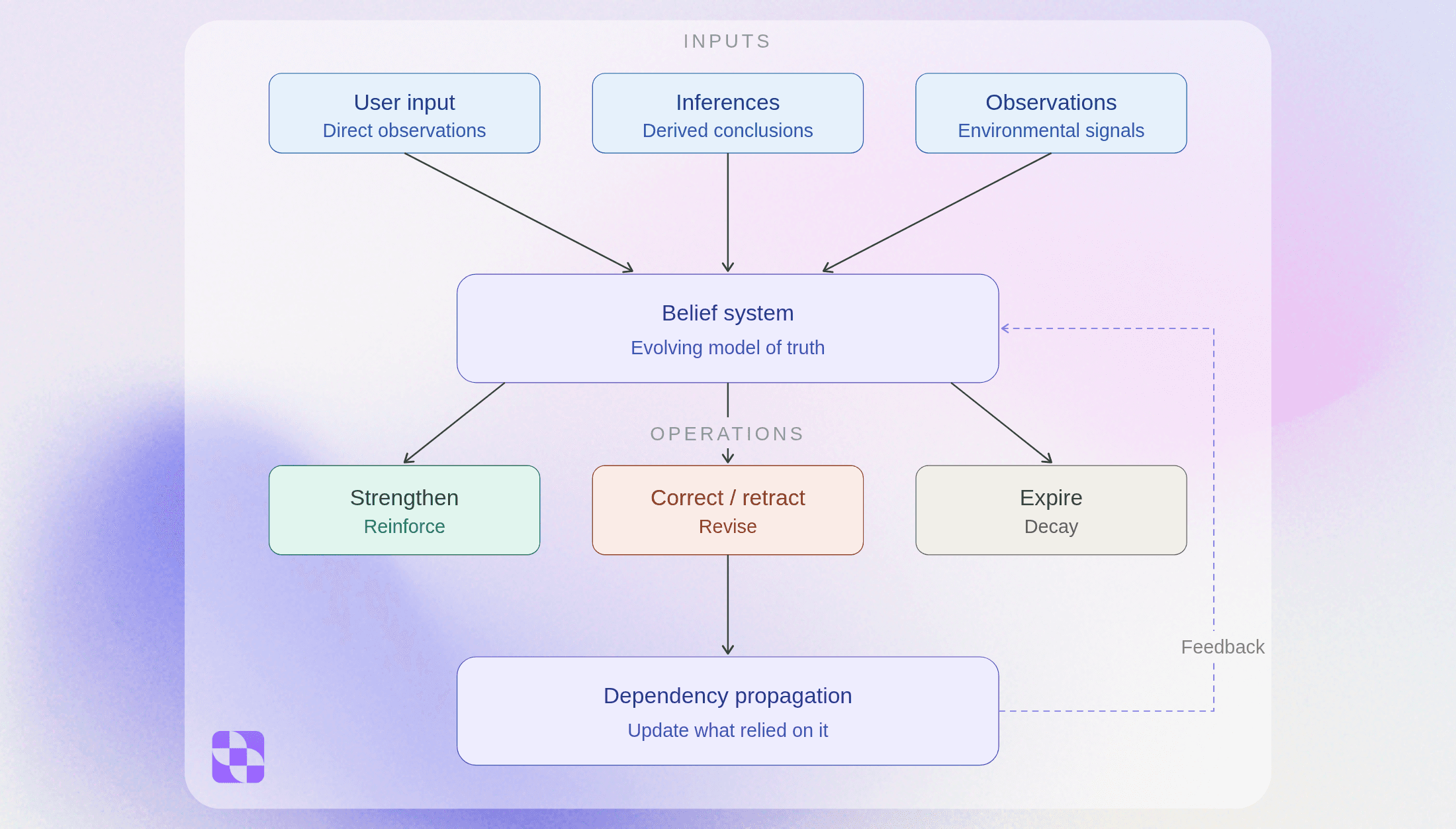
Core mechanics
Mechanism | System behavior | Outcome |
|---|---|---|
Entrenchment | Beliefs carry weight. Axioms are protected. What the user says outranks system guesses. | No silent overrides. The system doesn’t drift away from what’s actually true. |
Contraction | Beliefs can be removed cleanly. The system distinguishes real-world change from system error. | No stale context. Old beliefs don’t linger or corrupt future retrievals. |
Dependency propagation | When a belief changes, anything built on it is flagged — downstream beliefs and artifacts. | Context stays consistent as things change. No hidden breakage. |
Learning from corrections | Every correction is stored as a labeled mistake and retrieved in similar future situations. | The system improves over time without retra |
What the agent knows about itself
The system maintains two complementary sets of beliefs:
Your beliefs. The agent knows YOU — preferences, decisions, work products, constraints. This is everything described above.
The agent’s beliefs. The agent knows ITSELF — what tools work for which tasks, which skills to invoke for which user, where its own extraction biases are. “The search tool returns better results with specific queries.” “This user always wants a code review before committing.” “I over-infer dietary preferences from restaurant discussions.” Operational wisdom accumulated from outcomes, not programmed from a static prompt.
Both follow the same revision principles. Both use the same infrastructure. One serves the user. The other makes the pipeline better.
Where this is going
Today: session briefings, artifact handoff with version history, inline belief extraction with two-phase consolidation. The belief revision core — entrenchment, contraction, temporal scoping — is live.
Next: axiom management, dependency flagging across beliefs and artifacts, correction-aware extraction prompts, cross-tool context sharing.
The vision: Three people, three tools, three roles. The PM builds competitive analysis in ChatGPT. The engineer writes technical design in Claude. The tech writer documents in Notion. All connected to the same belief system. The PM’s decisions and artifacts flow to the engineer without re-explaining. When the PM changes a decision, the engineer’s agent flags both the stale beliefs and the artifacts built on them. The tech writer inherits the research, the design, and the full version history. Agents that share a world model. Context that compounds instead of degrading.
The thesis
The storage problem is solved. The maintenance problem isn’t.
Memory without revision degrades into noise. Revision without learning repeats its mistakes. Learning without structured memory has nothing to learn from.
The belief revision stack is all three: memory that maintains itself, revision that follows formal principles, and a learning loop that turns every correction into better extraction. The organizations that capture and maintain what their AI knows — the decisions, the reasoning, the evolving beliefs, the artifacts they produce — will compound their advantage. The ones that let it vanish with every new session will keep starting over.
Ready to implement?
If you are looking to integrate the belief revision engine into your own multi-agent workflows, our technical documentation provides the API references, SDKs, and integration guides needed to get started.